style: bullet
min_depth: 2
max_depth: 6
title: "**Contents**"
TL; DR
SPLADE is a neural retrieval model which learns query/document sparse expansion via the BERT MLM head and sparse regularization. Sparse representations benefit from several advantages compared to dense approaches: efficient use of inverted index, explicit lexical match, interpretability... They also seem to be better at generalizing on out-of-domain data (BEIR benchmark).
Intro
I have learned about SPLADE from the article: SPLADE for Sparse Vector Search Explained | Pinecone. Here below are the key concepts from the article (LLM summary)
The article discusses the evolution of search and recommendation systems, focusing on the shift from traditional "bag of words" methods to modern vector search. It explains how big tech companies like Google, Netflix, and Amazon use vector search to power their systems.
The traditional bag of words methods transform documents into a set of words, populating a sparse "frequency vector". While these methods are efficient and interpretable, they are not perfect due to their reliance on exact term matching, which doesn't align with human nature.
Dense embedding models offer a solution by allowing search based on semantic meaning. However, they require vast amounts of data for fine-tuning and don't perform well in niche domains where data is scarce.
The article introduces a solution to these problems: a merger of sparse and dense retrieval through hybrid search and learnable sparse embeddings. It focuses on SPLADE (Sparse Lexical and Expansion model), a model that uses a pretrained language model like BERT to enhance sparse vector embedding.
how it works
The idea behind the Sparse Lexical and Expansion models is that a pretrained language model like BERT can identify connections between words/sub-words (called word-pieces or “terms” in this article) and use that knowledge to enhance our sparse vector embedding.
This works in two ways, it allows us to weigh the relevance of different terms (something like the will carry less relevance than a less common word like orangutan). And it enables term expansion: the inclusion of alternative but relevant terms beyond those found in the original sequence.
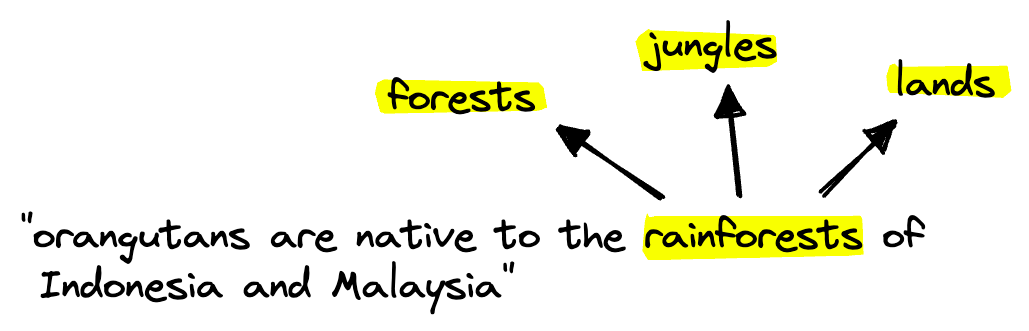
Term expansion allows us to identify relevant but different terms and use them in the sparse vector retrieval step.
The most significant advantage of SPLADE is not necessarily that it can do term expansion but instead that it can learn term expansions. Traditional methods required rule-based term expansion which is time-consuming and fundamentally limited. Whereas SPLADE can use the best language models to learn term expansions and even tweak them based on the sentence context.
The article also discusses the pros and cons of sparse and dense vectors, the concept of two-stage retrieval, and the drawbacks of this approach. It then looks into the workings of SPLADE, explaining how it builds sparse embeddings and how it can be implemented using Hugging Face and PyTorch or the official SPLADE library.
The article concludes by acknowledging the limitations of SPLADE, such as its slower retrieval speed compared to other sparse methods, and suggests solutions to these problems. It also highlights the potential of mixing both dense and sparse representations using hybrid search indexes to make vector search more accurate and accessible.
References
[1] T. Formal, B. Piwowarski, S. Clinchant, SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking (2021), SIGIR 21
[2] T. Formal, C. Lassance, B. Piwowarski, S. Clinchant, SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval (2021)
- https://www.linkedin.com/posts/prithivirajdamodaran_%3F%3F%3F%3F%3F%3F-%3F%3F%3F%3F-%3F%3F%3F%3F%3F%3F%3F%3F-activity-7164581754270400512-Aa87?utm_source=share&utm_medium=member_desktop